
Demographic data like server logs are more valuable than many shop user think. With server logs we identify user groups, push valuable products or do customer specific shop marketing with data lying around on the server. In this blog post I will describe how to use the data in a theoretical way with a book selling online shop.
Identify the customer
First of all, lets divide the customers in two groups. Traditional customers buy printed books and innovative ones buy other types like audio books. To filter the customers we have to prepare the log data and bring the data together to form sessions. Sessions contain all server log entries from a specific IP address starting with the the first view of the shop until he leaves it. An access to a SuperTracker Database can help to validate and add additional attributes and characteristics to the sessions. After defining the sessions they have to be filtered into useful and useless ones. Useless sessions are caused by bots and customers with only one or two log entries who accidentally visited the shop.
(Suchacka & Chodak, 2017)
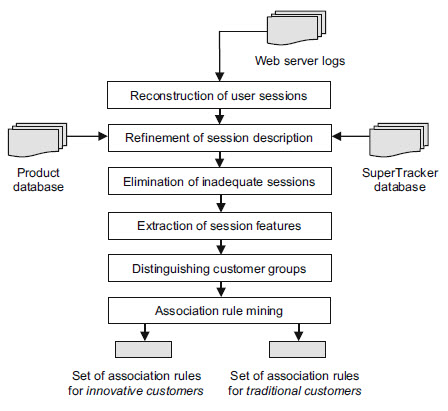 ###### Association rule generation framework for a B2C website (Suchacka & Chodak, 2017)
###### Association rule generation framework for a B2C website (Suchacka & Chodak, 2017)
Classification of sessions
After the session filter, every session will be classified. Basic Classifications can be the time duration on the shop, how many pages were visited or the time duration on a specific page. These classified sessions can also be more detailed classified. The classification parameters can be wich browser was used, the login status of the customer, did the customer add some products into the basket or actually performed an order. Using the data with an A-priori algorithm, events can be identified, which improves the chances of customer orders.
(Suchacka & Chodak, 2017)
Result click stream analysis
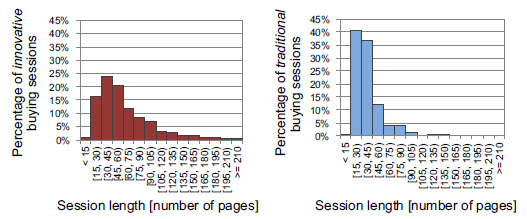 ###### Histogram of session lengths for buying sessions for innovative and traditional customers (Suchacka & Chodak, 2017)
###### Histogram of session lengths for buying sessions for innovative and traditional customers (Suchacka & Chodak, 2017)
In our case traditional customer perform orders very fast and innovative customers wander longer through the shop before perform an order. Another result of the analysis determine 89 percent of innovative customers perform an order by entering the shop with a link from a search engine, add an article in the basket and open up to 45 pages on the system. Traditional customers have a tendency of 92 percent to perform an order after login in, visit 30 to 75 pages and be in the shop around 10 to 25 minutes. With these results customer group specific marketing can be performed. We can improve our page views of innovative customers by adding more optimised ads in search engines.
(Suchacka & Chodak, 2017)
Gender prediction
Another way to use the session data is to predict the customers gender and show specific landing pages to them. For gender prediction we have to classify and filter the session in other ways. We do not want only to know how long the customer was on one page or in the shop but also in which season and on which day and month of the year. The amount of viewed products is also a possible filter for the sessions. Another group of data can be formed by display the categories and products in a binary tree view and show every switch and view of the category and product pages on this tree. With machine learning algorithm like Random Forest, Support Vector Machine, BayesNet or Gradient Boosting Decision Trees, we can predict the gender from sessions.
(Duc Duong et al., 2016) (Lu et al., 2015)
Machine learning algorithms
- Random Forest is a classification method working with decision trees. Through randomising the decision tree is growing and at the end, the class with the most votes will be chosen.
- Support Vector Machine classifies the data with hyperplanes in the vector space of the objects.
- BayesNet consists of a directed acyclic graph with various nodes and edges, which are randomised variables and conditional dependencies between the variables.
- Gradient Boosting Decision Trees create weak classifications which will be combined to one strong classification.
To choose the right method for learning with test data depends on how balanced the data is. With unbalanced Data like 80 percent women and 20 percent men, a “Cost-Sensitive Learning” method is needed to minimise the total costs and therefore get a higher statistically percentage for the right gender prediction.
(Duc Duong et al., 2016)
Result of gender prediction
In the end it depends on the quality of the data and the chosen algorithm how high the percentage for the right gender prediction is. Two teams at a tournament from FPT Corporation of PAKDD’15 performed with the given dataset a 81,4 percent correct prediction for both gender and the other team a 95 percent correct prediction of the female and a 77 percent correct prediction of the male gender.
(Duc Duong et al., 2016) (Lu et al., 2015)
Literature
- Suchacka, G., & Chodak, G. (2017). Using association rules to assess purchase probability in online stores. Information Systems and E-Business Management, 15(3), 751–780. https://doi.org/10.1007/s10257-016-0329-4
- Duc Duong, Hanh Tan, & Son Pham. (2016). Customer gender prediction based on E-commerce data. In 2016 Eighth International Conference on Knowledge and Systems Engineering (KSE) (pp. 91–95). IEEE. https://doi.org/10.1109/KSE.2016.7758035
- Lu, S., Zhao, M., Zhang, H., Zhang, C., Wang, W., & Wang, H. (2015). GenderPredictor: A Method to Predict Gender of Customers from E-commerce Website. In 2015 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT) (pp. 13–16). IEEE. https://doi.org/10.1109/WI-IAT.2015.106